Evaluating the price of a financial instrument implies most of the time to compute the expectation of a deterministic function of a random variable. This arises typically when the financial instrument payoff at maturity, noted $f$, depends on the unknown realization of some underlying(s), represented by a random variable $X$, assumed to follow a certain distribution.
The price is therefore, under a specific probability measure, $ \mathbb{E}[f(X)] $, that is the expectation of $f(X)$.
In computational finance, this calculation must often be approximated by some numerical approach, as there isn’t any closed formula available for returning this result.
A frequently used method to compute this expectation is the Monte Carlo method.
To compute the expected value using Monte Carlo, one simulates the random variable many times, and take the average of all $n$ outcomes.
The Monte Carlo estimator is therefore given by the expression
$$ MC(n) = \frac{1}{n}\sum_{i=1}^n f(X_i) $$where the $X_i$ are independent random draws of $X$.
The more simulations are run, the closer the estimate gets to the true expected value.
The convergence of this estimator is proportional to the standard deviation:
$$ \frac{\sqrt {Var(f(X))}}{\sqrt{n}} = \frac{\sigma_{f(X)}}{\sqrt{n}} $$Indeed using the central limit theorem, we have the confidence interval
$$ \mathbb{E}[f(X)] \in \left[ MC(M) - q_{\alpha} \frac{ \bar{\sigma}_M}{\sqrt{M}} \text{,} MC(M) + q_{\alpha} \frac{ \bar{\sigma}_M}{\sqrt{M}} \right] $$where
- $ q_{ \alpha} $ is the $ \alpha $ quantile of the normal distribution, and
- $ \bar{\sigma}_M $ is an estimation of the standard deviation of $f(X)$.
As our goal is to increase numerical efficiency or accuracy of this calculation, we can either:
- Improve the convergence of our Monte Carlo estimator for a given number of simulations
- Achieve the same accuracy than the Standard Monte Carlo estimator but using less simulations
A usual trick to achieve this enhancement is the Importance Sampling (IS) method. It’s part of a broader family known as variance reduction techniques.
Its aim is to reduce the variance of a Monte Carlo estimator, thus accelerating its convergence speed.
As this method is very general from a theoretical standpoint, it’s widely used in various domains such as physic, biology, economy, …
Moreover, this method can also be implemented in a generic way, making it particularly suitable for wide use in LexiFi’s financial calculation platform.
Principle
The idea behind the importance sampling is to reduce the statistical uncertainty of Monte Carlo calculation by focusing on the most important region of the space from which the random samples are drawn. Such regions depend both on the random variable simulated, and the structure of the financial contract priced.
Importance Sampling means essentially that one is modifying the stochastic behavior of the Monte Carlo approach (by modifying how the realizations $X_i$ are drawn). To obtain nevertheless the same result for the expectation calculation, one has to adjust the random variable $f(X)$ in a deterministic way.
It is the combination of a modification of the probability law of $X$ with a deterministic change of the outcome $f$ that allows the targeted enhancement of the Monte Carlo method: better statistical quality of the estimator while keeping it converging to the true expectation.
This method is indeed based on a modification of the sampling distribution to be more “adapted” to the problem (here the payoff of the financial contract) we are solving.
Example of distribution mapping:
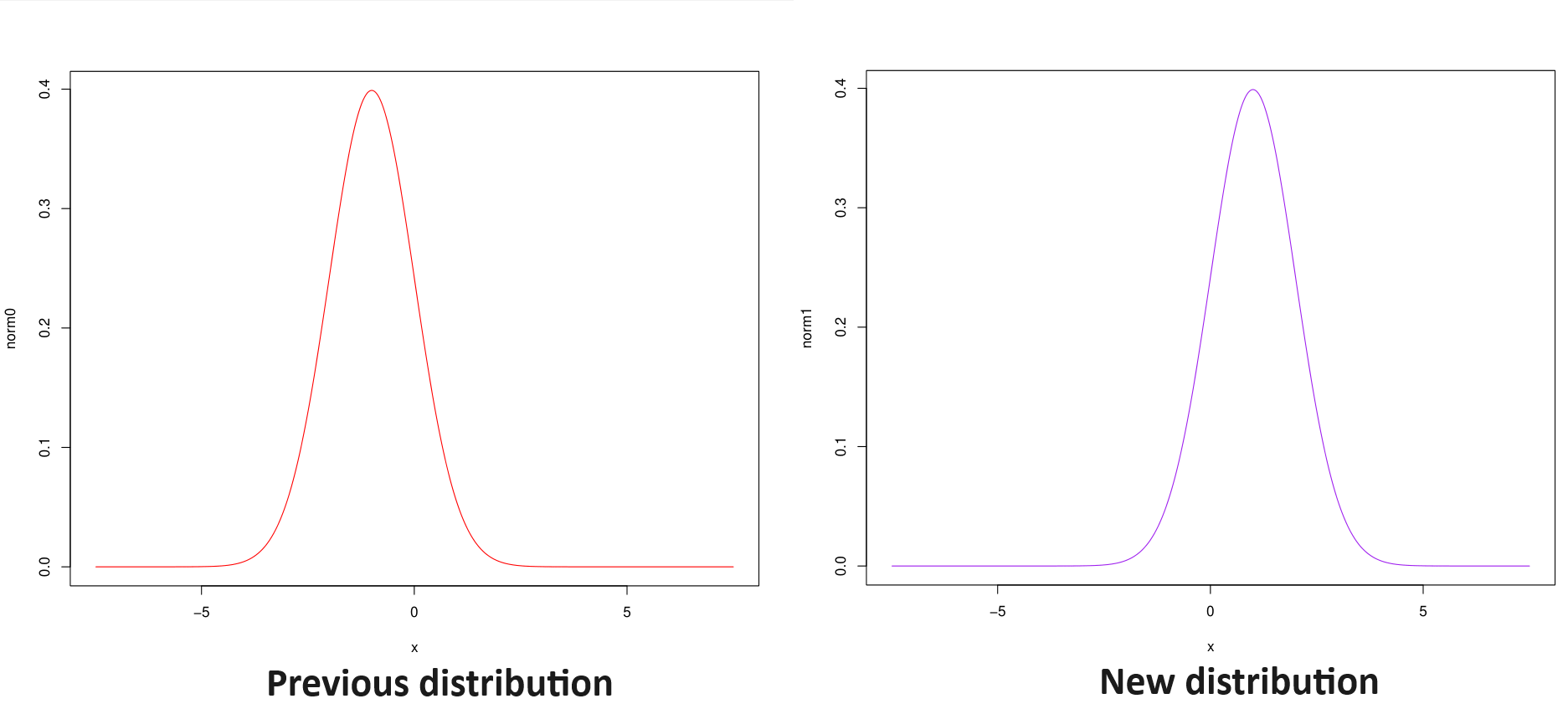
Let $\mathbb P$ be the probability under which our Monte Carlo estimator is initially expressed.
Let $\mathbb Q$ be another probability, equivalent to $\mathbb P$.
The same expectation can be evaluated in two different ways:
| Under initial probability | Under new probability |
|---|---|
| $$ \mathbb{E}^{\mathbb{P}}\left[f(X)\right] $$ | $$ \mathbb{E}^{\mathbb{Q}}\left[ f(X) \frac{d\mathbb{P}}{d\mathbb{Q}} \right] $$ |
Note that previous equality works for any probability $\mathbb{Q}$ equivalent to $\mathbb{P}$, so doesn’t give us any hint about how to choose a good or even best one.
By reducing the set of admissible other probabilities, we will make the problem tractable and provide an efficient way to find in this set a “best” new probability.
Following notations will be used below:
- $n$: number of simulations
- $d$: number of factors
- $n_t$: dimension of the time discretization
Monte Carlo (MC) estimator
Let’s apply this method to the Monte Carlo estimator.
Let’s note:
- $X_i^{\mathbb{P}}$ a set of realization of $X$ under ${\mathbb{P}}$
- $X^{\mathbb{Q}}_i$ a set of realization of $X$ under $\mathbb{Q}$
- $D(X^{\mathbb{Q}}_i)$ a set of realization of $\frac{d\mathbb{P}}{d\mathbb{Q}}$ under $\mathbb{Q}$
We have
| MC estimator under initial probability | MC estimator under new probability |
|---|---|
| $$ MC^{\mathbb{P}}(n) = \frac{1}{n}\sum_{i=1}^n f(X^{\mathbb{P}}_i) $$ | $$ MC^{\mathbb{Q}}(n) = \frac{1}{n}\sum_{i=1}^n f(X^{\mathbb{Q}}_i) D(X^{\mathbb{Q}}_i) $$ |
Note that if
$$ Var^{\mathbb{Q}}\left(f(X) \frac{d{\mathbb{P}}}{d{\mathbb{Q}}}\right) < Var^{\mathbb{P}}(f(X)) $$$MC^{\mathbb{Q}}(n)$ is a MC estimator of $ \mathbb{E}^{\mathbb{P}}\left[ f(X) \right] $ that converges faster than $MC^{\mathbb{P}}(n)$.
Our goal will therefore be to find a probability $\mathbb{Q}$ that minimizes $Var^{\mathbb{Q}}\left(f(X) \frac{d{\mathbb{P}}}{d{\mathbb{Q}}}\right)$.
Adapted to the pricing case
Let’s apply this generic variance reduction method to the specific case of financial contract valuation.
For reading purposes, we expose the pricing formula in the one dimension case.
Fundamental theorem of asset pricing (initial probability)
The price of a product at t is the actualized expected value of the future cash flows under the risk neutral probability knowing the information at t \begin{align*} {\color{blue} Price_t} & = {\color{green} \mathbb{E}}^{\color{orange} \mathbb{P}} \left[ {\color{red}e^{-\int_{t}^{T} r_u du }} {\color{magenta}\text{Payoff}(S_T)} | {\color{olive} \mathcal{F}_t } \right] \newline & = \displaystyle {\color{green} \int_{\Omega} } {\color{red}e^{-\int_{t}^{T} r_u du }} {\color{magenta}\text{Payoff}(s)} {\color{orange} p(s) } {\color{green}ds} \end{align*}
Applying a probability change, the new pricing formula becomes:
Fundamental theorem of asset pricing (new probability)
The price of a product at t is the actualized expected value of the future cash flows multiplied by the probability change under the new probability measure knowing the information at t \begin{align*} {\color{blue} Price_t} & = {\color{green} \mathbb{E}}^{\color{orange} \mathbb{Q}} \left[ {\color{red}e^{-\int_{t}^{T} r_u du }} {\color{magenta}\text{Payoff}(S_T)} {\color{teal}\frac{p(S_T)}{q(S_T)}} | {\color{olive} \mathcal{F}_t } \right] \newline & = \displaystyle {\color{green} \int_{\Omega} } {\color{red}e^{-\int_{t}^{T} r_u du }} {\color{magenta}\text{Payoff}(s)} {\color{teal}\frac{p(s)}{q(s)}} {\color{orange} q(s) } {\color{green}ds} \end{align*}
Let us now apply this approach to the mostly encountered case in financial derivatives evaluation, when uncertainty is driven by Gaussian random variables.
Implemented case: Gaussian change of probability
MC estimators for prices usually uses factors that are Gaussian variables.
For most standard models, the source of randomness (Equities, Volatilities, Foreign exchange, Commodity, Inflation,…) are driven by a Brownian motion.
Let $Z^i$ be a family of $d$ independent Gaussian variables. We want to estimate
$$ \mathbb{E}^{\mathbb{P}} [ {f(Z^i)} ] $$The Monte Carlo estimator is then
$$ \frac{1}{n}\sum_{j=1}^n f(Z^i_j) $$where $(Z^i_j)$ is the $j-th$ realization of $Z^i$.
Switching to a new probability, we get:
| MC estimator under initial probability | MC estimator under new probability |
|---|---|
| $$ \mathbb{E}^{\mathbb{P}} \left[ f(Z^i) \right] $$ | $$ \mathbb{E}^{\mathbb{Q}} \left[ f(Z^i) \frac{d\mathbb{P}}{d\mathbb{Q}} \right] $$ |
| $$ \frac{d\mathbb{P}}{d\mathbb{Q}} = \prod_{i = 1}^d \frac{\phi(Z^i)}{\phi_{\mu_i, \sigma_i}(Z^i)} $$ |
where $\phi_{\mu, \sigma}$ is the density of $\mathcal N(\mu, \sigma^2)$, and $\phi = \phi_{0, 1}$ the density of $\mathcal N(0,1)$.
Probability change, explanation (click to expand)
We want to change the mean and standard deviation of the Gaussian variables.\begin{split} \mathbb{E}^{\mathbb{P}} \left[ f(Z^i) \right] &= \int_{\mathbb R} f(z^i) \prod_{i = 1}^d \phi(z^i) dz^i \newline &= \int_{\mathbb R} f(\mu_i + \sigma_i z^i) \prod_{i = 1}^d \phi(\mu_i + \sigma_i z^i) \sigma_i dz^i \newline &= \int_{\mathbb R} f(\mu_i + \sigma_i z^i) \prod_{i = 1}^d \sigma_i \frac{\phi(\mu_i + \sigma_i z^i)}{\phi(z^i)} \prod_{i = 1}^d \phi(z^i) dz^i \newline &= \mathbb{E}^{\mathbb{Q}} \left[ f(Z^i) \frac{d\mathbb{P}}{d\mathbb{Q}} \right] \end{split}
where
\begin{split} Z^i & \stackrel{\mathbb{Q}}{\sim} \mathcal N (\mu_i, \sigma_i^2) \newline \frac{d\mathbb{P}}{d\mathbb{Q}} & = \prod_{i = 1}^d \frac{\phi(Z^i)}{\phi_{\mu_i, \sigma_i}(Z^i)} \end{split}
From Gaussian variables to Brownian processes
In practice, Gaussian variables are used to simulate Brownian increments. We’ll thus re-parameterize our estimator:
| MC estimator under initial probability | MC estimator under new probability |
|---|---|
| $$ \mathbb{E}^{\mathbb{P}} \left[ f(Z^i) \right] $$ | $$ \mathbb{E}^{\mathbb{Q}} \left[ f(Z^i) \frac{d\mathbb{P}}{d\mathbb{Q}} \right] $$ |
| $$ \frac{d\mathbb{P}}{d\mathbb{Q}} = \displaystyle \prod_{j=1}^d \left(\frac{\phi(Z^{i,j})}{\phi_{\mu_j\sqrt{\delta t_i}, \sigma_j}(Z^{i,j})}\right)^{n_t} $$ |
Probability change, explanation (click to expand)
Let $n_t$ the number of time discretization. Let $(t_i)_{0 \leq i \leq n_t}$ be the simulation dates for our $d$ brownians. Let $Z^{i,j}$ be the Gaussian variables needed for the $i$-th increment of the $j$-th Brownian motion: $$ W^j(t_i) - W^j(t_{i-1}) = \sqrt{\delta t_i} Z^{i,j} $$Where
$$ \delta t_i = t_i - t_{i-1} $$We want to use a parameterization such that in the new probability, we change both the drift and the volatility of each Brownian motion, ie.
$$ W^i(t) \stackrel{\mathbb{Q}}{\sim} \mathcal N(\mu_i t, \sigma_i^2 t) $$And in terms of $Z$:
$$ Z^{i,j} \stackrel{{\mathbb{Q}}}{\sim} \mathcal N(\mu_i \sqrt{\delta t_i}, \sigma_i^2) $$And the corresponding density for the change of probability is
$$ \frac{d\mathbb{P}}{d\mathbb{Q}} = \prod_{j=1}^d \left(\frac{\phi(Z^{i,j})}{\phi_{\mu_j\sqrt{\delta t_i}, \sigma_j}(Z^{i,j})}\right)^{n_t} $$Remark on the probability change parameters dimension
We change the mean $ \mu $ and the dispersion $ \sigma $ of each of the $d$ driving Brownian motions (risk factor).
We therefore express the new probability with $2 \times d$ parameters (independent of the dates).
If we take as an example the (one dimensional) Stochastic Local Volatility with Hull White one factor model (SLV/HW), we have one risk factor for:
- The underlying
- The volatility of the underlying
- The short rate
We have therefore 3 risk factors; for each of them, we may change the mean $ \mu $ and the dispersion $ \sigma $, so we have a total of 6 parameters to chose from.
Efficient optimization
Having developed the methodology and the setup in the financial application, our goal is now to find the optimal parameters. This problem is clearly an optimization one. We have to find the parameter such that the variance is minimal.
\begin{align*} & \underset{{\theta_{\mu}, \theta_{\sigma}}}{\text{minimize}} & & {\mathbb{V}ar}^{{ \mathbb{P}}^{ {\theta_{\mu}, \theta_{\sigma}}} } \left[ {e^{-\int_{t}^{T} r_u du }} { \frac{q(S_T)}{p^{ {\theta_{\mu}, \theta_{\sigma}}}(S_T)}} { Payoff(S_T)} \right] \end{align*}
As expectations are equal for all possible probabilities, this problem is equivalent to the following one
\begin{align*} & \underset{{\theta_{\mu}, \theta_{\sigma}}}{\text{minimize}} & & {\mathbb{E}}^{{ \mathbb{P}}^{ {\theta_{\mu}, \theta_{\sigma}}} } \left[ \left( {e^{-\int_{t}^{T} r_u du }} { \frac{q(S_T)}{p^{ {\theta_{\mu}, \theta_{\sigma}}}(S_T)}} { Payoff(S_T)} \right)^2 \right] \end{align*}
Note that for each value of the optimization parameters, we need to evaluate:
- The payoff
- The probability change
To avoid the payoff evaluation, we evaluate previous expectation under the initial probability, allowing us to express our problem in following equivalent form
\begin{align*} & \underset{{\theta_{\mu}, \theta_{\sigma}}}{\text{minimize}} & & {\mathbb{E}}^{{ \mathbb{P}} } \left[ \left( {e^{-\int_{t}^{T} r_u du }} { Payoff(S_T)} \right)^2 { \frac{q(S_T)}{p^{ {\theta_{\mu}, \theta_{\sigma}}}(S_T)}} \right] \end{align*}
Using this expression, the algorithm will be:
- Simulate $ n \times d \times n_t $ Gaussian variables
- Evaluate the $Payoff$ $n$ time on the initial Gaussian variables
- For each iteration of the minimizer, evaluate $ n $ times the probability change $ \frac{d{\mathbb{P}}}{d{\mathbb{Q}}} $
Because this probability change is cheap to evaluate, this optimization procedure is highly efficient from a computation time point of view.
For a complete explanation of those expressions, please expand the following paragraph.
Calibration proof (click to expand)
The method presented here is mainly based on [GZL] and [LB]If we want to minimize the variance, we need to find $(\mu_j, \sigma_j)_{1 \leq j \leq d}$ that minimize
$$ Var^{\mathbb{P}}\left(f(Z^{i,j})\frac{d{\mathbb{P}}}{d{\mathbb{Q}}}(Z^{i,j}) \right) $$We fist note that
\begin{split} Var^{\mathbb{Q}}\left(f(Z^{i,j})\frac{d{\mathbb{P}}}{d{\mathbb{Q}}}(Z^{i,j}) \right) &= \mathbb{E}^{\mathbb{Q}} {f(Z^{i,j})\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})}^2 \newline &= \mathbb{E}^{\mathbb{Q}} {\left(f(Z^{i,j})\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})\right)^2} - \underbrace{\mathbb{E}^{\mathbb{P}}{f(Z^{i,j})}^2}_{\text{does not depend on }\mathbb{Q}} \end{split}
Thus, minimizing variance is equivalent to minimizing
$$ \mathbb{E}^{\mathbb{Q}}{\left(f(Z^{i,j})\frac{d{\mathbb{P}}}{d{\mathbb{Q}}}(Z^{i,j})\right)^2} $$This expectation can be approximated using a Monte Carlo estimator. Let $N^{i,j}_k$ be realizations of $\mathcal N(0,1)$.
\begin{align*} \mathbb{E}^{\mathbb{Q}}{\left(f(Z^{i,j})\frac{d{\mathbb{P}}}{d{\mathbb{Q}}}(Z^{i,j})\right)^2} &\approx \frac{1}{n} \sum_{k=1}^n \left(f\left(\mu_j\sqrt{\delta t_i} + \sigma_j N^{i,j}_k\right) \frac{d{\mathbb{P}}}{d{\mathbb{Q}}}\left(\mu_j\sqrt{\delta t_i} + \sigma_j N^{i,j}_k\right)\right)^2 \end{align*}
If we want to numerically minimize this empirical variance, we can:
- Simulate $n \times d \times n_t$ Gaussian variables
- For each iteration of the minimizer:
- Evaluate $f$ $n$ times on the scaled and shifted Gaussian variables
- Evaluate $ \frac{d{\mathbb{P}}}{d{\mathbb{Q}}} $ $n$ times
If the minimizer converges using $n_m$ steps, then $f$ is evaluated $n_m \times n$ times, which can be really expensive, as $f$ is the composition of the evaluation of the payoff, to the computation of the trajectory on a model given uncorrelated Gaussian variables.
In order to reduce the number of required evaluation of $f$, we note that
\begin{align*} \mathbb{E}^{\mathbb{Q}} \left[ {\left(f(Z^{i,j})\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})\right)^2} \right] &= \mathbb{E}^{\mathbb{Q}} \left[ {\left(f(Z^{i,j})^2\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})\right)\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})} \right] \newline &= \mathbb{E}^{\mathbb{P}} \left[ {\left(f(Z^{i,j})^2\frac{d\mathbb{P}}{d\mathbb{Q}}(Z^{i,j})\right)} \right] \newline & \approx \frac{1}{n} \sum_{k=1}^n \left(f\left(N^{i,j}_k\right)^2 \frac{d{\mathbb{P}}}{d{\mathbb{Q}}}\left(N^{i,j}_k\right)\right) \end{align*}
Using this approximation instead, the minimization will:
- Simulate $n \times d \times n_t$ Gaussian variables
- Evaluate $f$ $n$ time on the initial Gaussian variables
- For each iteration of the minimizer, evaluate $\frac{d{\mathbb{P}}}{d{\mathbb{Q}}}$ $n$ times
We now have only $n$ evaluations of $f$, instead of $n_m \times n$ previously. Because the evaluation of $\frac{d\mathbb{P}}{d\mathbb{Q}}$ is cheap (compared to the evaluation of $f$), the new algorithm is way faster.
Another major point is that when expanding the change of variable term, we are able to compute explicitly the partial derivative thanks to the drift and to the dispersion terms. This allows to implement a fast numerical optimization algorithm (we have access to the expression of the function and its Jacobian).
Applications
We focus on two ways of using the importance sampling approach in the context of expectation computation. Those points make also sense for most of the commonly used variance reduction techniques.
Application 1: Improve accuracy
We suggest following algorithm to compute a Monte Carlo price estimator, using automatic Importance Sampling:
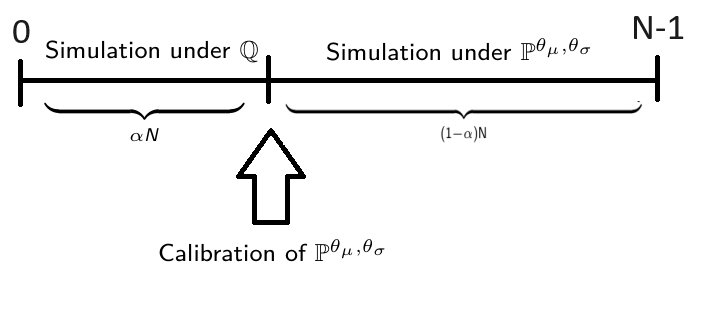
Let $N$ be the total number of Monte Carlo trajectories, and $n_0 = \alpha N < N$ be the number of trajectories used to infer the optimal change of probability.
- simulate $n_0 = \alpha N $ trajectories for the Gaussian variables: $$(N_k^{i,j})_{1 \leq i \leq n_t, 1 \leq j \leq d, 1 \leq k \leq n_0}$$
- evaluate $\alpha N$ times the $\text{Payoff}$ and store the evaluations: $$ \text{Payoff}_k := \text{Payoff}\left(N^{i,j}_k\right) $$
- find the optimal $ (\mu^{\ast}_j, \sigma^{*}_j) $ by minimizing $$ \sum_{k=1}^{n_0} \left(\text{Payoff}_k \frac{d{\mathbb{P}}}{d{\mathbb{Q}}}\left(N^{i,j}_k\right)\right) $$
- the remaining $N-n_0+1 = (1 - \alpha) N $ trajectories are computed using the optimal $ (\mu^{\ast}_j, \sigma^{*}_j) $ , and the final MC estimator is: $$ \frac{1}{n_0}\sum_{k=1}^{n_0} \text{Payoff}_k + \frac{1}{n-n_0}\sum_{k=n_0+1}^N \text{Payoff}\left(\mu^*_j\sqrt{\delta t_i} + \sigma^*_j N^{i,j}_k\right) \frac{d{\mathbb{P}}}{d{\mathbb{Q}}^*}\left(\mu^*_j\sqrt{\delta t_i} + \sigma^*_j N^{i,j}_k\right) $$
Following scheme summarizes this procedure:
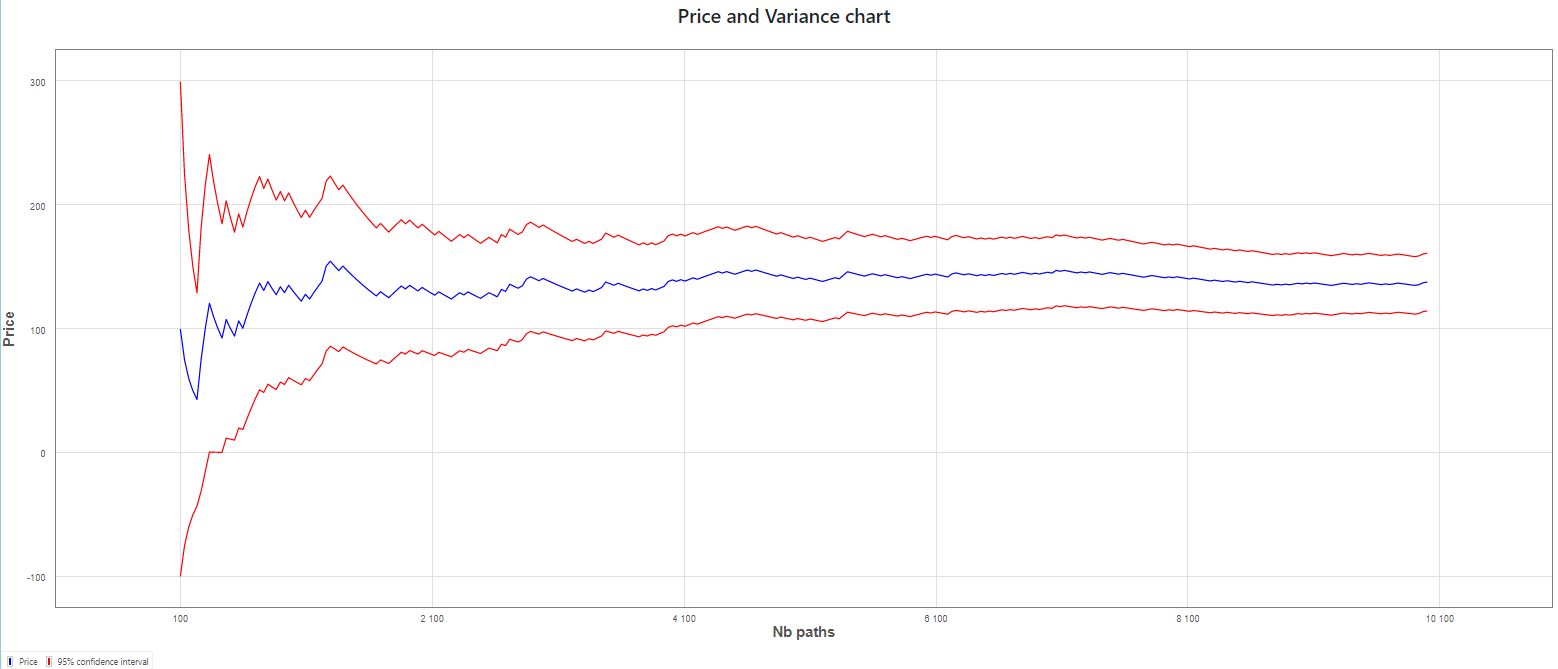
As an illustrative example, we apply this approach to the pricing of an autocall product:
- Here is the standard Monte Carlo estimator of the price with a 95% confidence interval
- For the same computation time, we are able to compute an estimator of the price using the importance sampling method with 9250 paths
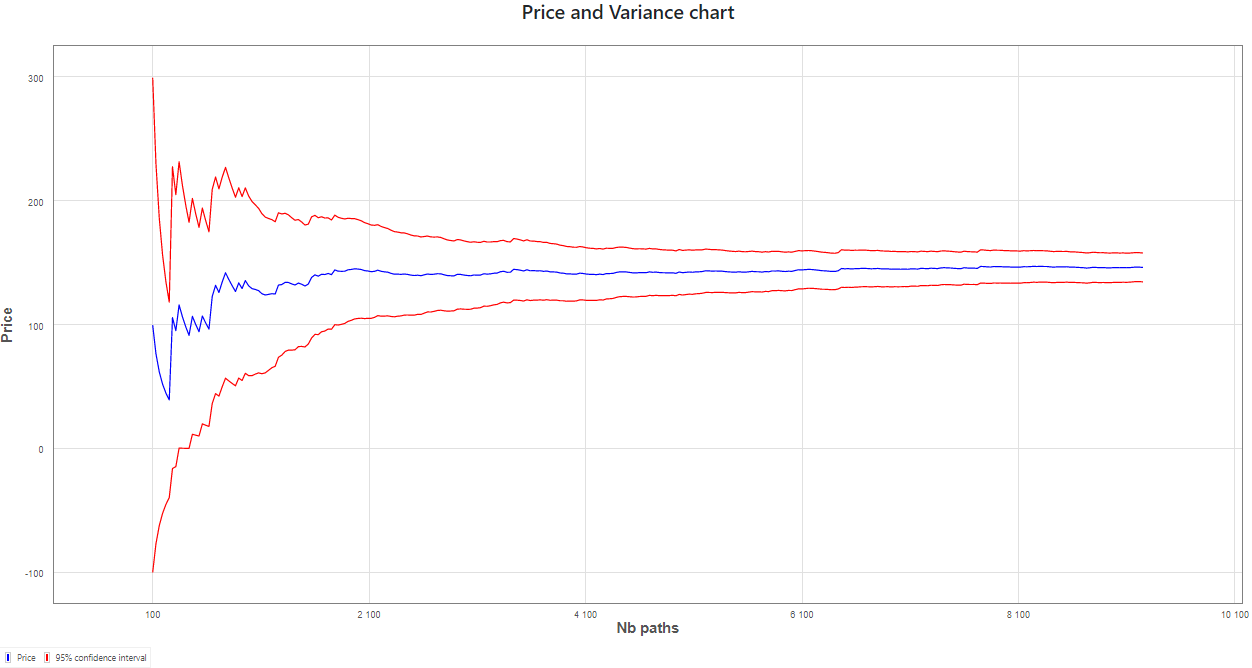
The confidence interval is, as expected, clearly reduced.
Empirical evidence:
| Method | Lower bound | Upper bound |
|---|---|---|
| Without IS | $$114.42$$ | $$160.99$$ |
| With IS | $$134.68$$ | $$157.95$$ |
The careful reader will also observe the increased “regularity” in the second chart, once Importance Sampling is activated, after optimization has been done, following initial simulations.
Application 2: Improve speed
The Importance Sampling will decrease the variance at a given number of trajectories, which will reduce the statistical error or the estimator (it will reduce the size of its confidence interval). We can also think of a mode that improve pricing speed, by decreasing the number of trajectories, without affecting the statistical error.
Here is a scheme that put in a nutshell this idea
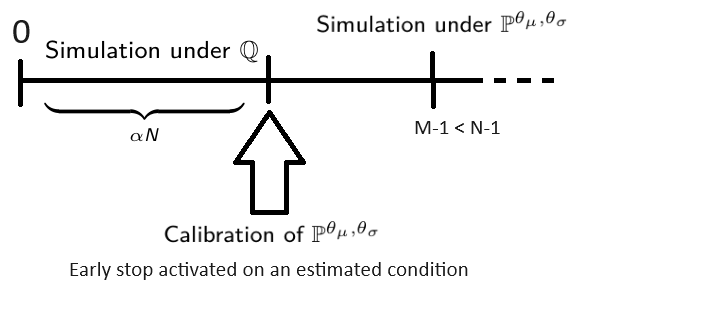
More details on speed mode (click to expand)
We recall that, by applying the central limit theorem, the MC estimator $MC(n)$ can be approximated by a Gaussian law, centered on the true expectation $\mathbb{E}^{\mathbb{P}}{[f(X)]}$, with variance $\sigma^2 = \frac{Var(f(X))}{n}$:
$$ MC(n) \approx \mathcal N\left(\mathbb{E}^{\mathbb{P}}{[f(X)]}, \frac{Var(f(X))}{n} \right) $$Thus, we have the confidence interval for the price, with probability $\alpha$:
$$ [MC(n)-k(\alpha)\sigma ; MC(n)+k(\alpha)\sigma] $$Typically, $k(\alpha) \approx 1.96$ for $\alpha = 95\%$
Let $\tilde{f(X)}$ be the random variable simulated with Importance Sampling applied. Theoretically, if we want to reach the same precision as without Importance Sampling, we want to stop at $n_e$ such that
$$ \frac{Var(\tilde{f(X)})}{n_e} \leq \frac{Var(f(X))}{n} $$To do that, $Var(f(X))$ can be estimated using the $n_0$ first simulations, that have been used for the inference of the optimal change of probability, and $Var(f(X))$ can be estimated for each trajectory, until the condition is empirically verified.
However, we note that this method is not perfect, because:
- We use an empirical estimation of the variance
- We use Sobol rng, that breaks usual statistical properties
In order to take these issues into account, we apply a ratio $R$ to our condition:
$$ \frac{Var(\tilde{f(X)})}{n_0} \leq R^2 \frac{Var(f(X))}{n} $$We calibrated the ratio $R$ on a realistic database of 5,000 autocalls, under Black-Scholes, Local Volatility and Heston models, with a reference price computed using 100,000 trajectories and Importance Sampling. We found that a ratio of $80\%$ allows to have statistically equivalent errors with 10,000 trajectories without Importance Sampling, and with Importance Sampling in Speedup mode. We also found that the risk of degradation when enabling Importance Sampling in speedup mode is the same as when disabling this mode (quantified by the distribution of the absolute error difference between IS and No IS). As a matter of fact, the price is sometimes improved, sometimes degraded (about 50% in each case). For speedup analyses please refers to Technical documentation. In this study, the total pricing time decreases by $\approx 20\%$ in Speedup Mode, compared to No Importance Sampling.
In this example we use the same pricing with a standard Monte Carlo method as in previous example. We then compare it with a Monte Carlo method using the Importance Sampling for achieving same accuracy.
-
Monte Carlo estimator using 10000 paths
-
Monte Carlo estimator with Importance Sampling using 3200 paths
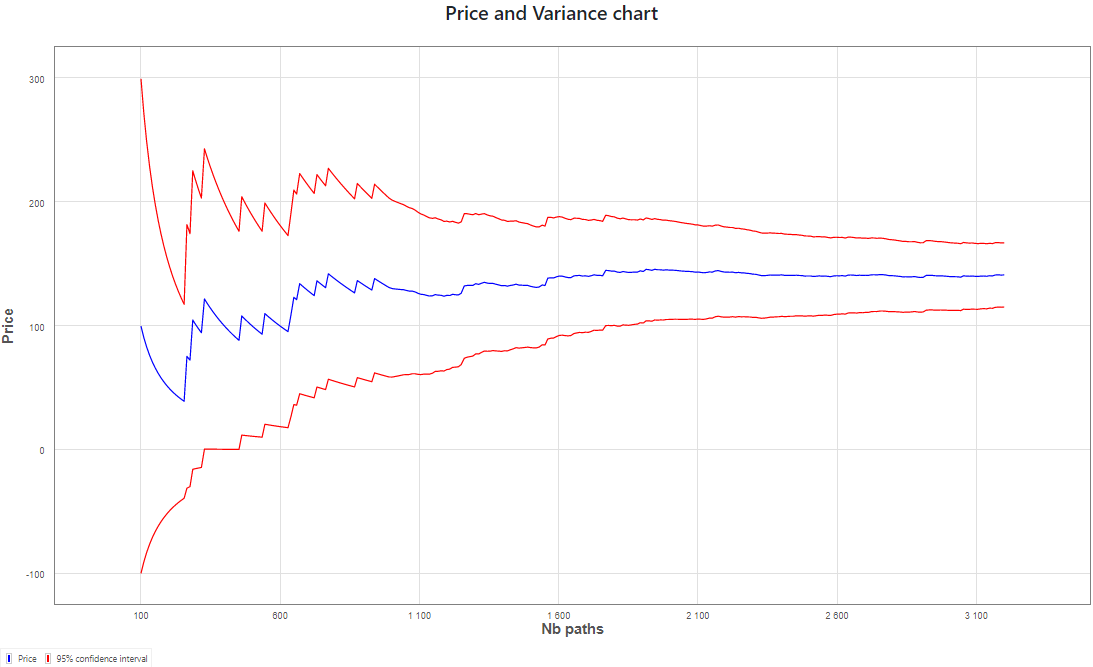
In this particular example, we achieve the same accuracy with only a third of initial number of paths. As initial optimization takes some computational time, we nevertheless achieve a computation that is 2.27 times faster.
Conclusion
We focus our attention on a variance reduction technique known as Importance Sampling and explore its application in the pricing field. A major point is that the sources of randomness come from the uncertainty of the future value of underlying assets, mostly modeled using Brownian motion.
One of the major issues is the choice of “optimal parameters” for the change of probability. Based on a theoretical study and a careful numerical implementation, we expose an efficient algorithm that involves a small number of payoff evaluation. Thanks to the analytic expression of the partial derivatives, the optimization itself converges very fast.
Once these parameters are determined, we apply this method to two modifications of the standard Monte Carlo procedure: to enhance accuracy or improve speed.
LexiFi’s highly integrated pricing engine allows for an efficient implementation of this approach, shared by all MC models available in LexiFi’s solution.
Because this approach is organized in a highly generic manner, it smoothly interacts with all other LexiFi’s Monte Carlo features including adjusters, Romberg Richardson method, efficient numerical schemes, American feature, … and all the applications of LexiFi solution.
References
[GZL] Guiding Gu Qiang Zhao, Guo Liu. Variance Reduction Techniques of Importance Sampling Monte Carlo Methods for Pricing Options. Journal of Mathematical Finance, January 2013, www.researchgate.net
[LexiFi] LexiFi model documentation, Importance Sampling, www.lexifi.com
[LB] Jérôme Lelong Benjamin Jourdain. Robust adaptive importance sampling for normal random vectors. The Annals of Applied Probability, November 2008, //arxiv.org