Poisson distribution is a classical distribution that often appears in mathematical finance, like in jump diffusion. In this article, I will present an efficient simulation method under the constraint to use only one random variate per simulation.
This constraint is useful when using low-discrepancy sequence for instance.
The Poisson distribution
The Poisson distribution with parameter $\lambda$ is a discrete probability distribution, with positive values and whose probability mass function is given by \[ f(k, \lambda) = \mathbf P(P = k) = \frac{\lambda^ke^{-\lambda}}{k!} \]
Its mean $\mu_P(\lambda)$ is $\lambda$ and its variance $\sigma_P(\lambda)^2$ is $\lambda$. For the following, we provide also its skewness $S_P(\lambda)$ and its excess kurtosis $K_P(\lambda)$:
\begin{align*} S_P(\lambda) & = \mathbf E\left[\left(\frac{P - \mu_P(\lambda)}{\sigma_P(\lambda)}\right)^3\right] = \lambda^{-1/2}\ K_P(\lambda) & = \mathbf E\left[\left(\frac{P - \mu_P(\lambda)}{\sigma_P(\lambda)}\right)^4\right] - 3 = \lambda^{-1} \end{align*}
We note that Poisson variable (with parameters $\lambda$) can also be seen as the value at $t = 1$ of a counting process whose jumps are of size 1 and whose jump time are separated by an exponential distribution (with parameters $\lambda$).
Let $N$ be such a process, with $(\tau_i)_{i \geq 0}$ its jump times. $\forall i \geq 1, \tau_i - \tau_{i - 1} = E_i$ where $E_i \sim exp(\lambda)$. Then, $N(t) = \sum_{\tau_i \lt t} 1$ and $\tau_i = \sum_{j=0}^i E_j$. We have $P \buildrel \mathcal L \over = N(1)$
This remark provides a first idea to create a naive Poisson distribution simulation method (the exponential distribution is easy to simulate).
Naive Poisson distribution simulation methods
Using the previous remark, we can easily provide an algorithm to simulate the Poisson distribution:
1 2 3 4 5 6 7 8 9 | tau = 0 N = -1 while (tau <= 1) { E = simulate_exp(lambda) tau = Tau + E N = N + 1 } N |
But this algorithm violates our constraint. Indeed, most of the time we will simulate more than one random variable. Additionally, we don’t even know in advance how many variables we need.
Let's return to our constraint. The easier way to respect it is to use inversion algorithm. In this case, we have to simulate only one uniform variable per Poisson variable. Let $F$ be the cumulative distribution function of a discrete variable (and $f$ its probability mass function), $q$ the quantile function of $F$ defined by \[ q(u) = inf\{ k \in \mathbf N, u \leq F(k) \} \]
and let $U$ be a uniform variable. Then, $q(U)$ is $F$ distributed.
Proof: \begin{align*} \mathbf P (q(U) = k) &= \mathbf P (inf\{ l \in \mathbf N, U \leq F(l) \} = k)\\ &= \mathbf P (F(k - 1) \lt U \leq F(k))\\ &= F(k) - F(k - 1)\\ &= f(k) \end{align*}We can then apply this result to our case, and have a good idea to start. Now, the difficulty is to find an efficient way to compute the cumulative distribution function of a Poisson distribution. As we are still in the "naive simulation methods" part, we will see the most basic way to achieve this goal that will be used to benchmark the efficient solution we will propose later. To do that, we simply compute the quantile function using a basic search from $k = 0$ until $F(k - 1, \lambda) \lt u \leq F(k, \lambda)$, or just until $u \leq F(k, \lambda)$ (as we perform an increasing search, and $F$ is an increasing function). We use $F(k, \lambda) = F(k - 1, \lambda) + f(k, \lambda)$ to efficiently compute $F(k, \lambda)$ and $f(k, \lambda) = \frac{\lambda}{k}f(k - 1, \lambda)$. We propose then the following algorithm to compute (Naive Simulation):
1 2 3 4 5 6 7 8 9 10 11 12 13 | Q = function(lambda, u) { f = exp (-lambda) F = f k = 1 while (F < u) { f = lambda / k * f F = F + f k = k + 1 } k - 1 } |
The expected complexity of this algorithm is $\mu_P(\lambda) = \lambda$ (the number of iterations is a Poisson random variable). Then, the bigger $\lambda$ is, the less efficient this algorithm is.
The method
The proposed method is still based on a research of $k$ such that $F(k - 1, \lambda) \lt u \leq F(k, \lambda)$, but now instead of starting at $k = 0$, we start at $k = \bar q_{\lambda}(u)$, where $\bar q_{\lambda}$ is an easily computable approximation of the quantile function of a Poisson law with parameter $\lambda$. Such an approximation can be found using the Cornish-Fisher expansion.
The Cornish-Fisher expansion
The Cornish-Fisher expansion is a formula that approximates quantile (or realization) of any variable using standard Gaussian variable, based on the cumulant. In our case, we use the approximation with the 4 first cumulants, what leads to: \[ X \approx Z + (Z^2 - 1)\frac{S_X}{6} + (Z^3 - 3Z)\frac{K_X}{24} - (2Z^3 - 5Z)\frac{S_X^2}{36} \]
where $X$ is a variable we want to approximate with $0$ mean and $1$ variance, $Z$ a standard Gaussian variable, $S_X$ the skewness of $X$ and $K_X$ the excess kurtosis of $X$. This formula can be adapted with $Y$ with $\mu_Y$ mean and $\sigma_Y^2$ variance, applying the formula to $X = \frac{Y - \mu_Y}{\sigma_Y}$, and using the fact that skewness and excess kurtosis are invariant by affine transformation:
\begin{align*} \frac{Y - \mu_Y}{\sigma_Y} & \approx Z + (Z^2 - 1)\frac{S_Y}{6} + (Z^3 - 3Z)\frac{K_Y}{24} - (2Z^3 - 5Z)\frac{S_Y^2}{36}\ \Rightarrow Y & \approx \sigma_Y \left( Z + (Z^2 - 1)\frac{S_Y}{6} + (Z^3 - 3Z)\frac{K_Y}{24} - (2Z^3 - 5Z)\frac{S_Y^2}{36} \right) + \mu_Y \end{align*}
if we note $q_Y$ the quantile function of $Y$ and $q$ the quantile function of a standard Gaussian variable, we have:
\[ q_Y \approx \sigma_Y \left( q + (q^2 - 1)\frac{S_Y}{6} + (q^3 - 3q)\frac{K_Y}{24} - (2q^3 - 5q)\frac{S_Y^2}{36} \right) + \mu_Y \]We note that the right term of this formula must be a strictly increasing function for the approximation to hold.
Application to the Poisson distribution
We can use the previous formula in the case of the Poisson distribution:
\begin{align*} q_{\lambda} &\approx \lambda^{1/2} \left( q + (q^2 - 1)\frac{\lambda^{-1/2}}{6} + (q^3 - 3q)\frac{\lambda^{-1}}{24} - (2q^3 - 5q)\frac{\lambda^{-1}}{36} \right) + \lambda\ &= q \lambda^{1/2} + \frac{q^2 - 1}{6} + \frac{q - q^3}{72} \lambda ^ {-1/2} + \lambda \end{align*}
In our case, the function we want to approximate has positive integer value. Then, we set \[ \bar q_\lambda = R\left(q \lambda^{1/2} + \frac{q^2 - 1}{6} + \frac{q - q^3}{72} \lambda ^ {-1/2} + \lambda\right) \]
where $R(x)$ is the positive part of the rounding of $x$, ie $ R(x) = max(0, \lfloor x + \frac{1}{2}\rfloor)$.
Here are some examples of the precision of our approximation (the black curve is the exact function and the red one the approximated function):
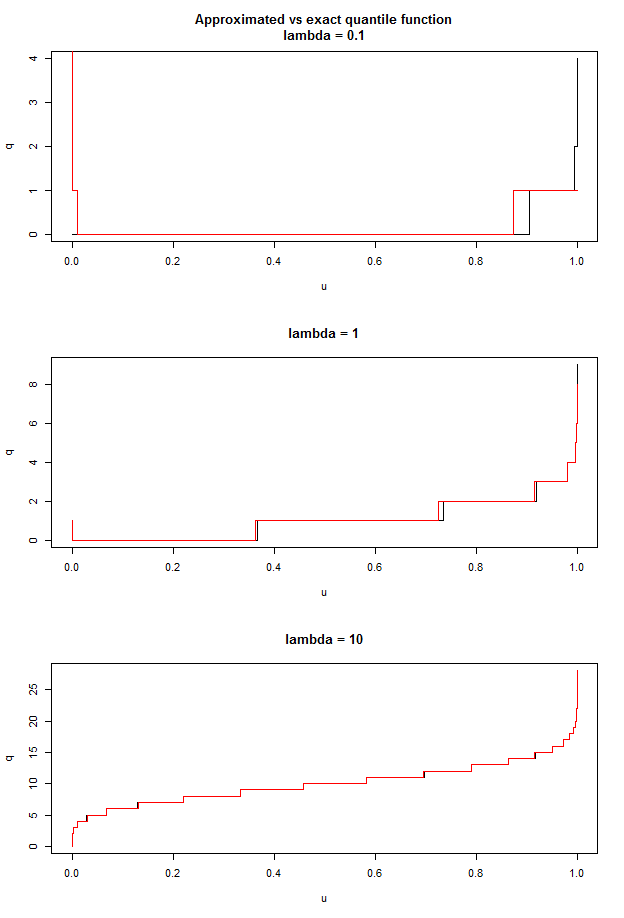
We see that:
- the bigger $\lambda$ is, the more the approximation is precise
- the approximation is poor near $u = 0$
- except the case $u$ close to $0$, the error is rarely bigger than one
This approximation is satisfying for a first guess in a search algorithm.
The complete method
The goal is to find $k$ such that $F(k - 1, \lambda) \lt u \leq F(k, \lambda)$. As told previously, we perform a search from $k_0 = \bar q_{\lambda}(u)$, or more precisely we perform the search for $u \in (F(0, \lambda); 1)$ (and return $k = 0$ otherwise).
The last issue we have to solve at this point is the computation of $F(\bar q_{\lambda}(u), \lambda)$, that has a linear complexity in its first argument if computed each time. The solution is to precompute in an array the $F(k, \lambda)$ for $k \in [0, n - 1]$. We note that this solution is only relevant when we have many computations of $F(\cdot, \lambda)$ for a fixed $\lambda$, ie when we have to simulate a lot of Poisson variables with the same intensity. This is the case in Monte Carlo method for instance. There are many ways to choose $n$ to control the error. For instance, we can fix $\epsilon > 0$, and choose $n$ such that $\mathbf P (P \geq n) < \epsilon$, or $\mathbf E (P | P \geq n) < \epsilon$. A last trick we can use to improve a little the algorithm is to hard-code the first cases using the precomputed array (the first must be in all case hard-coded due to the poor efficiency of the approximation near $0$ for small $\lambda$). It will be particularly efficient with small $\lambda$.
The final algorithm is then (Cornish-Fisher Simulation):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | buildQ = function(lambda) { F = precompute_F (lambda) F0 = F[0] F1 = F[1] ... n = length (F) function (u) { if (u <= F0) 0 else if (u <= F1) 1 ... else { q = gaussian_quantile(u) bar_q = q * sqrt(lambda) + (q^2 - 1) / 6 + (q - q^3) / (72 * sqrt(lambda)) + lambda bar_q = max(0, floor(bar_q + 0.5)) if (bar_q >= n) bar_q else if (u <= F[bar_q - 1]) decreasing search from bar_q - 1 else if (F[bar_q] < u) increasing search from bar_q + 1 else bar_q } } } |
Remark: The inverse of the Gaussian cumulative distribution function can replaced with an approximation (e.g. using this approximation for $erf^{-1}$).
Results and conclusion
I implemented the two algorithm in R, then the timing can be high, but what matter is the ratio between methods. In the (CFS) method, I hard-coded the 5 first cases.
In all test case, I take $10^5$ numbers uniformly distributed between 0 and $1 - 10^{-10}$.
Here are my results:
| $\lambda$ | 0.01 | 0.1 | 0.5 | 1 | 5 | 10 | 50 | 100 |
| NS | 0.34 | 0.38 | 0.45 | 0.56 | 1.44 | 2.40 | 10.70 | 20.80 |
| CFS | 0.20 | 0.21 | 0.22 | 0.25 | 0.94 | 1.33 | 1.35 | 1.36 |
| Ratio | 1.67 | 1.81 | 2.00 | 2.24 | 1.54 | 1.80 | 7.91 | 15.24 |
We see that for all $\lambda$, the (CFS) method is faster than the (NS) method. For small $\lambda$, it is due to the hard-coding of the first few tests. For big $\lambda$, it is due to the constant complexity of (CFS), while the complexity of (NS) is $\lambda$ in average.
The (CFS) method is designed to work very well for simulation of a large number of Poisson variables with the same intensity. However, it will be particularly inefficient when intensities are not constant. An example of problems that can be solved using this method are Monte Carlo method when some underlying distributions are Poisson law. This is the case for instance for pricing in jump models with compound Poisson process, like Merton or Bates models. The implementation in LexiFi of these two models use the (CFS) method, which leads to an efficient Monte Carlo method.